
Autores: Bengio, Yoshua; Ducharme, Réjean;
Vincent, Pascal;
Jauvin, Christian.
Keywords: Statistical language modeling, artificial neural networks, distributed representation,
curse of dimensionality.
Idioma: inglés.
A Neural Probabilistic Language Model
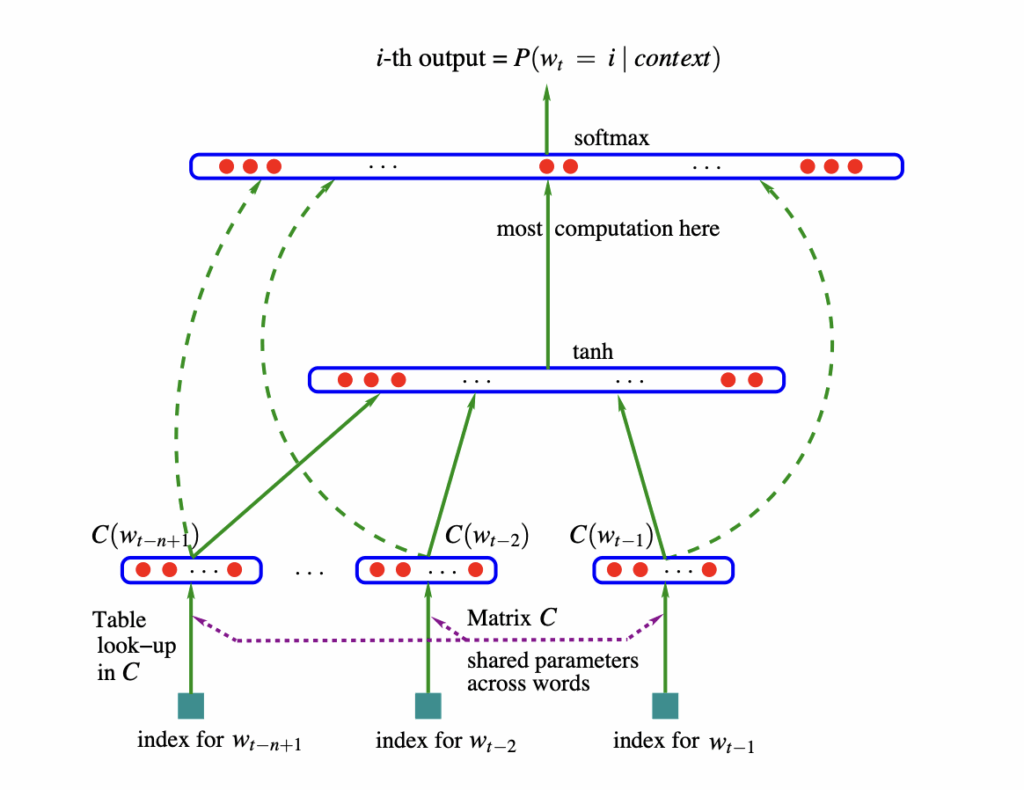
El modelado del lenguaje busca aprender la probabilidad de secuencias de palabras. Supera el problema de la rareza de estas (la “maldición de la dimensionalidad”) al aprender representaciones distribuidas (vectores) para cada palabra. Así, la similitud entre palabras permite generalizar y asignar alta probabilidad a frases nuevas compuestas por palabras similares a las ya vistas. Este modelo neuronal supera significativamente a los tradicionales n-gramas.

Autores: Kaiming, He; Xiangyu, Zhang; Shaoqing, Ren; Jian Sun
Keywords:
Año: 2015
Idioma: Inglés
Delving Deep into Rectifiers:
Surpassing Human-Level Performance on ImageNet Classification
Este trabajo mejora las redes neuronales para clasificación de imágenes. Introduce la Unidad Lineal Rectificada Paramétrica (PReLU), que mejora el rendimiento casi sin coste computacional adicional. También propone un método de inicialización robusto para entrenar redes muy profundas desde cero. Con estas mejoras, su modelo supera por primera vez el rendimiento humano en el dataset ImageNet.
Autores: Ashish Vaswani;
Llion Jones;
Noam Shaker;
Aidan N. Gomez;
Niki Parmar;
Jakob Uszkoreit;
Lukasz Kaiser
Keywords:
Año: 2017
Attention Is All You Need
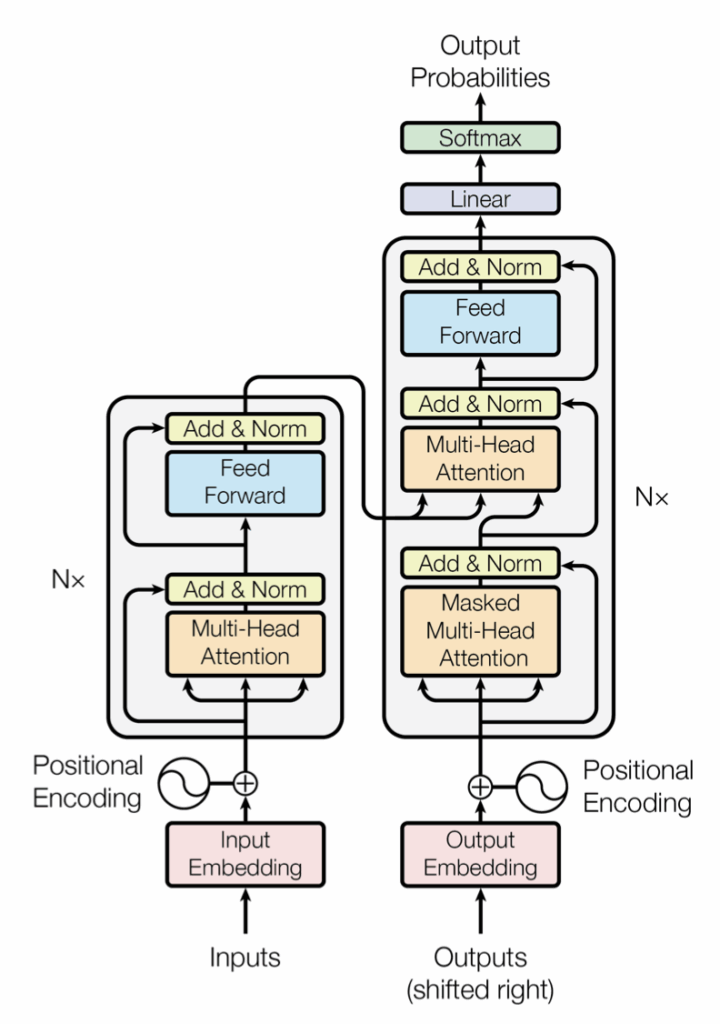
Se presenta el Transformer, una nueva arquitectura de red para traducción automática. A diferencia de los modelos dominantes, prescinde por completo de recurrencia y convoluciones, basándose únicamente en mecanismos de atención. Los resultados muestran que es superior en calidad, más paralelizable y requiere mucho menos tiempo de entrenamiento, estableciendo nuevos récords de precisión (BLEU) y eficiencia.
Autores: Lili Yu; Dániel Simig; Colin Flaherty; Armen Aghajanyan; Luke Zettlemoyer; Mike Lewis.
Keywords: transformers
Año: 2023
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
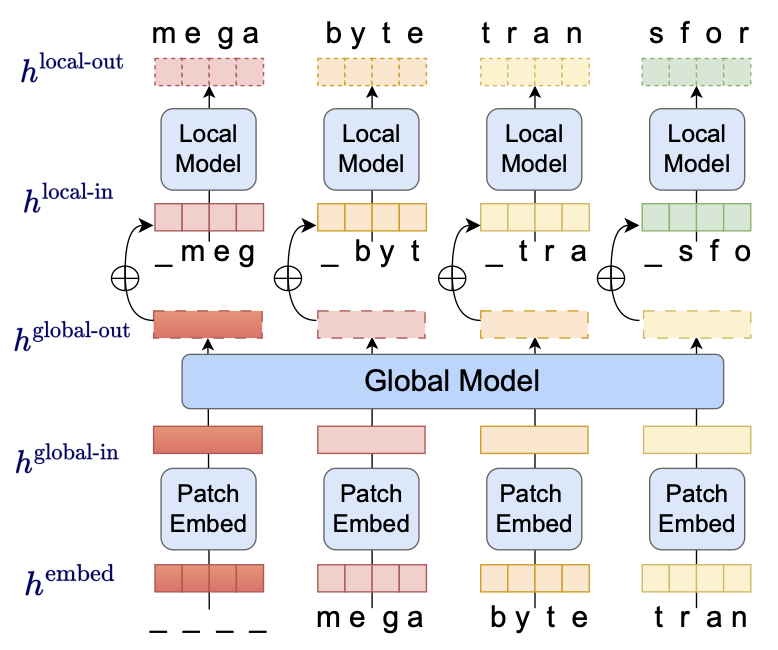
Se presenta MEGABYTE, una arquitectura que permite modelar secuencias extremadamente largas (más de 1M de bytes) de forma eficiente. Divide la secuencia en parches y usa un modelo local (dentro del parche) y otro global (entre parches), logrando una atención subcuadrática y mejor rendimiento con menos costo. Demuestra que es viable prescindir de la tokenización a gran escala.